
缺失值产生的原因:
缺失值的产生原因多种多样,主要分为机械原因和人为原因。机械原因是由机械导致的数据缺失,比如数据存储的失败、存储器损坏、机械故障导致某段时间的数据未能收集(对于定时数据采集而言). 人为原因是由人的主观失误或有意隐瞒造成的数据缺失.
从缺失的分布来看,缺失值主要分为以下三类:
- 完全随机丢失(Missing Completely at Random, MCAR): 即对于所有的观察结果,丢失的概率是相同,就是数据丢失的概率与其假设值以及其他变量值都完全无关,这种情况几乎不会发生。
- 随机丢失(Missing at Random, MAR): 即变量的值随机丢失并且丢失的概率会因其他输入变量的值或级别不同而变化,也就是说,数据的缺失不是完全随机的,该类数据的缺失依赖于其他完全变量。
- 非随机丢失(Missing Not at Random, MNAR):即数据不是随机缺失,而是受一些潜在因子的影响。
如何发现缺失值:
Pandas 内置了函数可以用来查看缺失值, 如下:
In [1]: df1["one"]
Out[1]:
a 0.469112
b NaN
c -1.135632
d NaN
e 0.119209
f -2.104569
g NaN
h 0.721555
Name: one, dtype: float64
In [2]: pd.isna(df1["one"])
Out[2]:
a False
b True
c False
d True
e False
f False
g True
h False
Name: one, dtype: bool.isna() 函数可以为我们找到所有的缺失值, 注意这里仅仅是Pandas默认的缺失值标记”NaN”, 其他如Python的缺失值标记”None”, 或者是人为的标记如”Missing Value”, “N/A”, “0”, 甚至是空值” “都有可能不被Pandas认为是缺失值, 对于这类缺失值需要结合对于数据集本身的理解, 在使用.isna()函数之前先进行处理,把这类标记转换成Pandas默认的缺失值标记”NaN”.
也可以使用.info()函数来查看整个Dataframe的缺失情况:
In [1]: df.info()
Out[1]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 316200 entries, 0 to 316199
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 316200 non-null object
1 age 316200 non-null int64
2 new_user 316200 non-null int64
3 source 316200 non-null object
4 total_pages_visited 316200 non-null int64
5 converted 316200 non-null int64
dtypes: int64(4), object(2)
memory usage: 14.5+ MB
我们也可以通过其他函数的组合来计算缺失率, 如下:
In [1]: (df1.shape[0] - df1["one"].count())/df1.shape[0]
Out[1]: 0.05 #缺失率是5%.shape()可以统计数据样本的个数, .count()可以统计不为空的统计数据样本个数, 所以求差除总数就是就是缺失率.
判断缺失分布:
一般情况下无非是两种,缺失随机丢失和非随机丢失,那么如何确实是哪一种情况?或者说如何确定某一特征的缺失性和target的关系呢?
我们可以新建一列indicators,并把某一个的特征的缺失性用0和1来表示,比如0为未缺失,1为缺失,这样新建的indicators列就全由0和1构成。然后再检查indicators列和其他特征的相关性,或者使用indicators来预测target, 如果indicator和其他特征存在一定的相关性或者indicator是好的预测特征,则证明这一个特征的缺失性和其他特征存在某种关联,即当前特征的缺失分布为非随机丢失,反之则为随机丢失。假如女性相较于男性更倾向于隐瞒自己的真实体重,则通过检查indicators和性别则会呈现强相关性。
当判断出属于哪一类的缺失分布以后,就可以使用不同的方法来处理了。
处理随机缺失:
1. 成列删除(List Wise Del)/成对删除(Pair Wise Del)
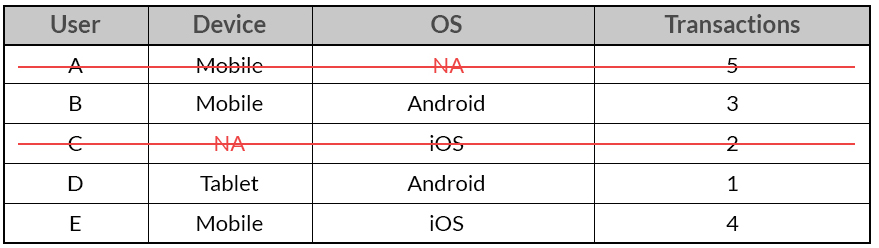
成列删除可能翻译成成行删除会更贴切, 这种方法简单粗暴, 直接删除任何存在feature丢失的样本, 但是这样可能会导致样本总量减少或者数据集不均衡, 从而导致模型拟合能力降低, 这个问题在大数据集上不明显.
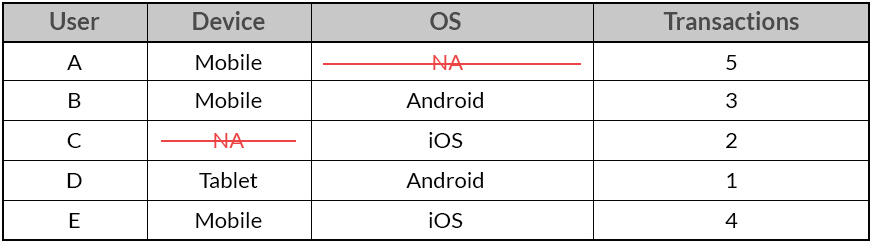
成对删除则是把对应的缺失值删掉, 这种方法可以保留更多的样本, 但是会导致每个样本的feature数量不同.
2. 统计量填充
统计量填充分为一般填充和相似样本填充, 定量属性采用平均数, 中位数, 而定性属性采用众数进行填充.
- 一般填充是使用该特征下所有非缺失样本的平均数, 中位数或者众数进行填充.
- 相似样本填充是利用具有近似特征的样本的平均数, 中位数或者众数进行填充.
统计量填充总的来说简单易行, 是低缺失率的首选. 特点是填充值相对稳定, 但是这种方法忽视了缺失值的不确定性。
3. 不处理
当我们在处理定性属性特征时,有些时候缺失总体不多的时候,也可以选择不处理,因为“缺失”本身也是一种标签,也在某种程度上告诉我们了一些信息。
处理非随机缺失:
1. 预测模型填充
即通过建立模型来预测缺失值, 比如使用随机森林。一般会把数据分成两份. 一份不存在缺失值的, 用作训练集, 另一份存在缺失值的作为测试集, 而缺失的变量就是预测的目标.
预测模型填充预测值也相对”规范”, 方差估计很好, 适用于高缺失率. 但是依赖于特征之间的相关性, 如果特征之间不存在关系, 则预测到的缺失值不准确, 同时在使用比较强大的模型时,要注意防止过拟合。
2. 多重插补(Multiple Imputation)

多重填补方法分为三个步骤:
插补:将不完整数据集缺失的观测行估算填充m次(图中m=3)。请注意,填充值是从某种分布中提取的。模拟随机抽取并不包含模型参数的不确定性。更好的方法是采用马尔科夫链蒙特卡洛模拟(MCMC,Markov Chain Monte Carlo Simulation)。这一步骤将生成m个完整的数据集。
分析:分别对(m个)每一个完整数据集进行分析。
合并:对来自各个填补数据集的结果进行综合,产生最终的统计推断,这一推断考虑到了由于数据填补而产生的不确定性。该方法将空缺值视为随机样本,这样计算出来的统计推断可能受到空缺值的不确定性的影响。